Home » Case Studies » Pipeline from the cloud to the Factory
Pipeline from the cloud to the Factory
Part 1 - The Challenges

Hercules had twelve challenges presented to him. We have three. Fair, I think, considering that he was a demigod.
Typically in machine learning:
- Models are trained using data that is created in an online platform and so then stored in the cloud as a consequence. This data is then readily accessible for pre-processing to train a model.
- Data labelling is done by humans, taken from existing labelled datasets or a combination of both.
- The selected models are then deployed to an endpoint online which is accessed through an API for predictions.
However, in the IoT space:
- The data is created by sensors locally and if it is stored at all it is stored locally, often for just a short period of time.
- Data is often unique to the device as a result of the physical environment it is collected in that is specific to the use case or the specifications of the combination of sensors used to collect the data. This unique, unlabelled data is collected in massive quantities.
- Models are frequently required to be deployed on the IoT device for reasons such as real-time, low latency prediction or simply because the device is not guaranteed to have a connection to the internet or any other device.
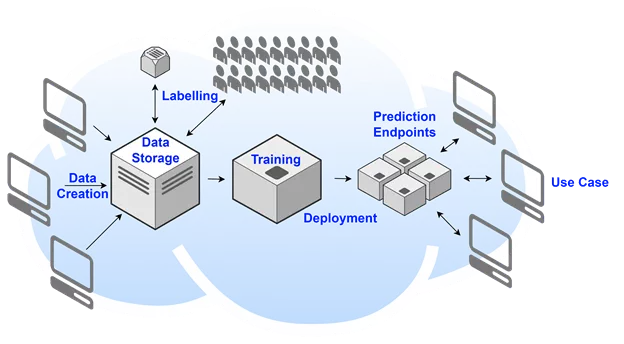
A typical machine learning solution
The challenges this environment presents are:
1. Getting DATA to The Cloud
for effective model training to take place the data must be accessible for training, and it is best accessed in the cloud where training processes can take advantage of the effectively unlimited amount and exhaustive variety of resources available. Therefore, any relevant data captured by the IoT devices must communicated to the cloud.
This means:
- The IoT device must have access to an internet connection in some way. This could be directly, or through connection to another device with internet connection.
- The IoT device must be able to store the relevant data for enough time to deal with periods where it may not have access to a connection to the internet.
2. DATA Labelling
the IoT space is characterised in part by the sheer amount of data that needs to be captured and processed. In itself this is challenging, but in the context of ML this presents an extra challenge:
- The data is likely unique to the sensors on which it was collected and environment in which it was collected. Therefore it is unlikely there are similar enough ready-labelled datasets available to train a model.
- The IoT device must be able to store the relevant data for enough time to deal with periods where it may not have access to a connection to the internet.
3. Model Training & Deployment to Embedded-tech
in embedded-tech, many of the hardware requirements are driven by the need for the device to be small and light. This in turn drives the software requirements, and the ML model requirements. The model likely has to be lightweight, be required to operate on a specific OS, and maybe with a limitation on the bit size of the data used. Also, each device must have its own copy of the model.
Therefore:
- Models deployed must run on the device exactly as it did in the machine that trained it. To achieve this, the training environment should be as similar as possible to device environment. For example, the IoT device may be limited to using an 8 bit OS, so the training should mimic this as having a 32 bit or 64 bit number in the model parameters could change the model behaviour entirely when deployed.
- Every time a model is updated it must be deployed to multiple devices. Some sort of automated version control and automated deployment process must be implemented for both deploying to new devices and deploying updates to existing devices.
- Multiple device versions (hardware or software) may be in use at the same time to perform the same task. This is builds upon points a. and b. above; models deployed should run the same on all devices performing the same task, and if this means different model files, this should be accounted for in the automated deployment process.
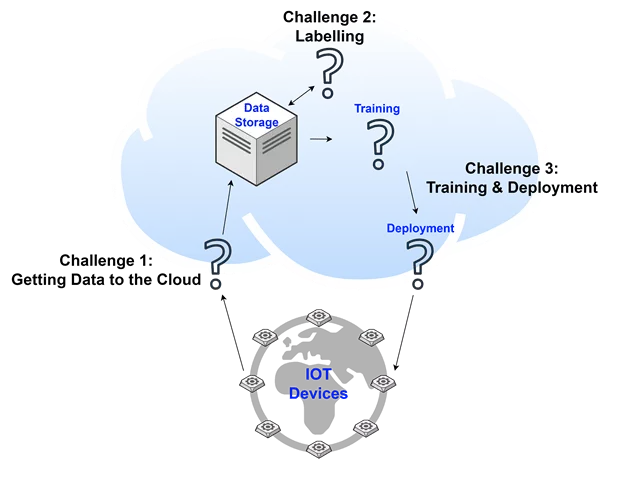
Challenges in IoT based ML Solutions
Part 2 - The Solutions

Like the story of Perseus and Medusa, we can see that lots of small and slippery challenges have a common solution at the source. Unlike in the case of Perseus and Medusa, the solution involves further integration rather than separation.
Getting Data to the Cloud
Data Labelling
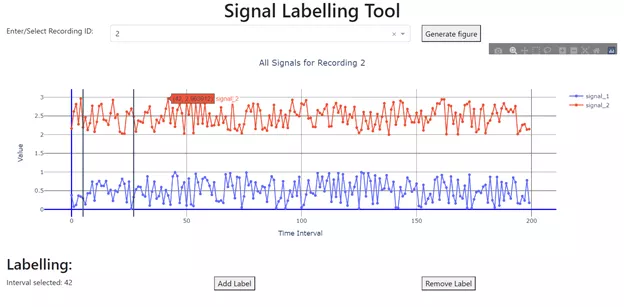
An example of a tool that could be used to label time series signals.
This is a risk-based and iterative approach:
- The higher the certainty threshold, the safer the auto-labelling, but the more time the expert must devote to labelling and vice versa.
- As a better understanding of the data evolves, so should this approach. For example, as models are trained, samples that were just below the model’s threshold for labelling as positive should be reviewed to: a) see if they may actually be positive samples, then b) how this information can be incorporated into the semi-supervised method. Otherwise, you are at risk of high precision, but low recall. That is, every point the model assigns a specific label has a very high probability of being correct (true positive), but it may only capture a very small number of points that should be assigned a label, and so produce lots of false negatives.
Model training & deployment to embedded tech
A managed ML platform like Amazon SageMaker is a flexible and powerful tool that provides the features to create a training and deployment solution that integrates well with the IoT space requirements. Within the platform, the SageMaker pipelines specifically provide the ability to create and manage ML life-cycle workflows, with the flexibility to address the challenges of working with ML in the IoT space, whilst also providing the scalability, repeatability, and automation expected of a modern ML life-cycle.
A. Matching The Environment in Training
When deploying trained models, the following are some generalised examples of approaches:
- Deploy the model file to a device running a code environment that is the same environment that it was trained in (e.g. Python 3.9, TensorFlow 2.8).
- Deploy a Docker image of the model to the device.
- Deploy just the trained parameters to a custom implementation of the model specific to the device (e.g. a lightweight C implementation).
Option 1 and 2 are common and applied in many ML deployments. However, option 3 is required in many IoT ML solutions due to the compute limitations producing the requirement to remove any superfluous processing from the prediction serving.
You will notice that the title of this subsection is “Matching the environment in training”, and using option 3 we are not really doing that. In fact, this reveals the issue that the best tools for training at big-data scale and the best tools for deploying at embedded IoT device scale are likely to be too inherently different to achieve the same software environment.
As a result of using different environments for training and inference, many more sources of possible error are introduced. This risk can be minimised (but not eliminated) by more robust processes to ensure the custom implementation of the model with pre-trained parameters applied gives the same results as the trained version with the same parameters. At the very least tests should run a range of inputs through both models and the outputs then compared for equality. Processes should also be put in place to monitor the model in the production environment; metrics such as prediction speed in the resource limited environment are also important in the decision of whether a model is appropriate to deploy.
Lets take the use case of voice-commanded robot-assistants as an example of how this may be implemented.
In this case we may find a Long Short-Term Memory (LSTM) based Deep Neural Network (DNN) is likely an appropriate architecture for the solution as it allows us to handle arbitrarily long time series input with information persistence in both the long and the short term (hence the name). This is especially useful for NLP (Natural Language Processing) models as it means the model can handle variable length sequences (e.g. multiple sentences of multiple words) and consider information from words that have just occurred as well as words or concepts that may have occurred a sentence or two before, but are still crucial to overall understanding.
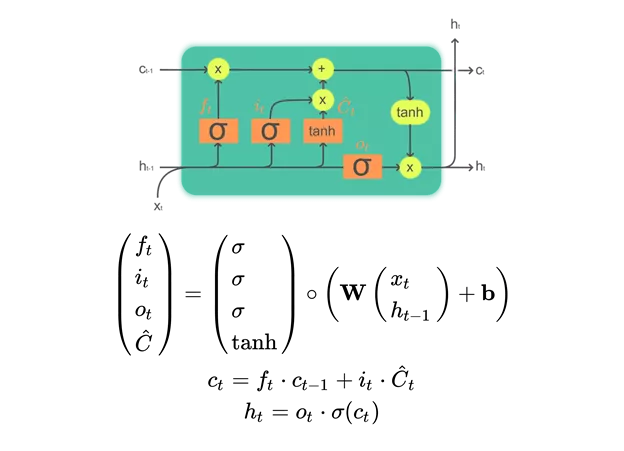
Matrix algebra representation of an LSTM node. Here `t` represents the time step in the sequence, sigma represents the sigmoid function.
B. Version Control & Automated Deployment
Sticking with the LSTM example for a moment, we can see how it the matrix implementation can minimise infrastructure requirements for deployment. By needing to deploy only the trained parameters most of the time this minimises the data transferred during deployment. This advantage is significant when deployment is required to potentially millions of IoT devices, where minimising data transferred can simplify the infrastructure requirements. Even deploying a whole model with an updated architecture with this minimal functionality implementation is significantly cheaper than a whole model with a package like TensorFlow or PyTorch. Versioning is still critical, however.
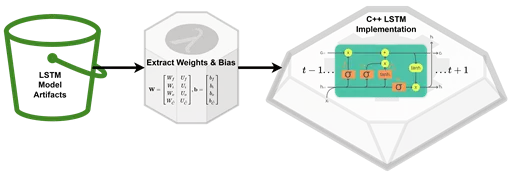
Matrix algebra representation of an LSTM node. Here `t` represents the time step in the sequence, sigma represents the sigmoid function.
Whatever versioning is implemented should identify what the use-case/context of each IoT device is, along with the current version of parameters and model architecture deployed. This then allows the correct set of new model parameters, or correct new model architecture, to be deployed when required. The models trained in the cloud should also have similar metadata associated; the architecture version they are compatible with and the data context they were trained in.
This is an example where having the right data architecture in place can significantly streamline the process. With this data architecture in place, parameters or model architectures can be deployed by a couple of simple scripts in some sort of lightweight automated process executor (e.g. a Lambda function). An orchestration script and a deployment pipe script. By just supplying the version of the weights to be deployed to the orchestrator, it can check which devices should be updated and trigger other executors to update those devices, then also updating versioning status information in the database if successful.
Final Words
The IoT space provides its challenges in ML related to the limitations imposed by requiring embedded hardware, high output of unique data, and the possibility of limited or no direct connection to the cloud. We demonstrate how a solution with appropriate architecture can leverage existing ML platforms to implement pragmatic, scalable processes for labelling and deployment to build a fit-for-purpose solution for the complete IoT ML life-cycle. Here we have seen a general approach to the solution, but the specific technologies utilised and approaches taken in any solution will depend on the business context of the IoT product in question.